scons用户指南(三)
第三章 编译相关的一些简单事情
本章你将会看到几个使用SCons的简单编译配置的例子,这些例子将描述从不同编程语言在不同类型系统上编译程序是多么简单的事情。
本章你将会看到几个使用SCons的简单编译配置的例子,这些例子将描述从不同编程语言在不同类型系统上编译程序是多么简单的事情。
本章你将会看到几个简单的利用SCons进行编译配置的例子,这些例子将描述利用Scons编译不同系统上的不同编程语言的程序是多么容易的事情。
最近想搞一下python的爬虫,就想起来学习一下scrapy。之前写过一些爬虫代码,都是利用beautifulsoup或者正则表达式对特定的网站html进行解析,爬取结束也就废弃了。
我下载的版本是scrapy-0.22的源码包,下载地址是http://scrapy.org/download/
本章将带你进行一下基础操作,在你的系统上安装scons以及编译scons。在这之前,本章将会先介绍下有关安装python的步骤。幸运的是,python和scons在几乎所有系统上的安装都很简单,并且python在许多系统上都会预先安装。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。有关JSON的知识,请参考《介绍 JSON》。
cJSON是一个用C语言实现的Json处理程序,代码量不大,只有一个头文件cJSON.h和一个源文件cJSON.c,用起来比较方便。从sourceforge上可以下载。
使用stl map或者unordered_map进行字符串查找一般都是用std::string类型作为key,但是std::string的效率实在太低,不得不进行优化,尝试使用char*作key来查找。
python处理字符串的时候经常用到unicode编码,特别是处理中文的时候,如下图:
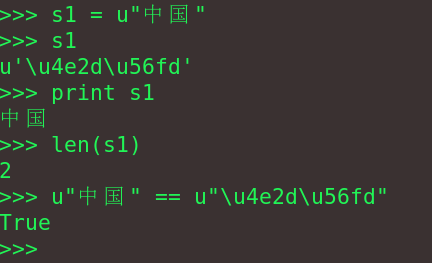
可以看出,u"中国"和u"\u4e2d\u56fd"是等价的,"中国"的unicode编码是\u4e2d\u56fd,其中\u是unicode编码的转义字符,类似\n,\r等。
由于训练语料的有限,大量的N-gram词语在训练语料中没有出现,而前文提到N-gram的训练一般采用最大似然估计的方法,这就导致了零概率问题。同时最大似然估计对于小频率词语的估计也很糟糕。这就是语言模型的数据稀疏问题。
为了解决数据稀疏问题,提出了一系列的平滑算法,基本思想是降低已出现N-gram条件概率分布,以使未出现的N-gram条件概率分布非零,且经数据平滑后保证概率和为1。
语言模型,是用来计算一个句子出现的概率,或者预测给定历史词语序列下,一个词语出现的概率。
S=w1,w2,w3,...,wn
P(S)=P(w1,w2,...,wn)=P(w1)P(w2|w1)P(w3|w1,w2)...P(wn|w1,...,wn-1)
其中P(S)就是该句子S的出现概率, P(wn|w1,...,wn-1)是给定历史(w1,w2,...,wn-1)下,词语wn出现的概率。
Tutorials:
Statistical Data Mining Tutorials Tutorial Slides by Andrew Moore http://www.autonlab.org/tutorials/
CS 281B / Stat 241B, Spring 2008:Statistical Learning Theory Readings http://www.cs.berkeley.edu/~bartlett/courses/281b-sp08/readings.html
Machine Learning Surveys:A list of literature surveys, reviews, and tutorials on Machine Learning and related topics http://www.mlsurveys.com/
机器学习经典论文/survey合集 http://suanfazu.com/discussion/68