统计语言模型
1. 语言模型简介
语言模型,是用来计算一个句子出现的概率,或者预测给定历史词语序列下,一个词语出现的概率。
S=w1,w2,w3,...,wn
P(S)=P(w1,w2,...,wn)=P(w1)P(w2|w1)P(w3|w1,w2)...P(wn|w1,...,wn-1)
其中P(S)就是该句子S的出现概率, P(wn|w1,...,wn-1)是给定历史(w1,w2,...,wn-1)下,词语wn出现的概率。
那么该如何计算句子概率P(S)呢?P(w1)很简单,w1的出现次数除以语料中的总词数,而从w2开始,
P(wn|w1,...,wn-1) = P(w1,...,wn-1,wn) / P(w1,...,wn-1)
在上式中,w1,...,wn-1,wn出现的可能有词表数量的n次方,当n比较大时,会导致这个参数空间过大,难以计算;另一方面,n越大,词串越长,在语料中出现的概率越小,会导致数据非常稀疏。
为了解决上述问题,伟大的马尔可夫提出了马尔可夫假设,即一个词语出现的概率仅与其前面出现的N个词语有关,也就是N-gram模型。 根据N的取值,有
- unigram:1-gram,词语出现仅与自身有关,P(S)=P(w1)P(w2)P(w3)...P(wn)
- bigram:2-gram,词语出现仅与前一个词有关,P(S)=P(w1)p(w2|w1)P(w3|w2)...P(wn|wn-1)
trigram:3-gram,词语出现仅与前两个词有关,P(S)=P(w1)p(w2|w1)P(w3|w2,w1)...p(wn|wn-1,wn-2)
...
理论上,N越大,约束性越好,辨别力更强,但是统计信息不足,因此一般bigram和trigram用的最多。
一般在构造语言模型时采用最大似然估计来进行概率估计,也就是通过计算词串在语料中出现的次数来计算相应的概率
P(wn|w1,...,wn-1) = P(w1,...,wn-1,wn) / P(w1,...,wn-1)
= C(w1,...,wn-1,wn) / C(w1,...,wn-1)
为了表征句子首尾,会在句首添加符号,在句末添加。
在构造时,为了避免数据溢出、提高性能,通常会使用取log后使用加法运算替代乘法运算,log一般以10为底的对数。
2. 评价标准
语言模型构造完成后,如何确定好坏呢? 目前主要有两种评价方法:
- 实用方法:通过查看该模型在实际应用(如语音识别、机器翻译)中的表现来评价,优点是直观、实用,缺点是缺乏针对性、不够客观;
- 理论方法:困惑度(Perplexity),其基本思想是给测试集赋予较高概率值的语言模型较好,公式如下:
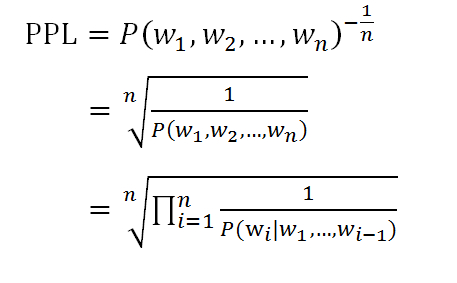 Perplexity越小,句子概率越大,语言模型对测试集的表征越好,在相应的应用中的表现也会越好。在语音识别领域,一般情况下,识别的错误率会随着perplexity的减小而减小。
Perplexity越小,句子概率越大,语言模型对测试集的表征越好,在相应的应用中的表现也会越好。在语音识别领域,一般情况下,识别的错误率会随着perplexity的减小而减小。
3.主要应用
语言模型主要应用在一下领域:
- 语音识别(Automatic Speech Recognition,ASR)
- 统计机器翻译(Statistical Machine Translation,SMT)
- 拼写纠正(Spelling Correction)
- 手写体识别(Handwriting Recognition)
- 自然语言生成(Natual Language Generation,NLG) ...
未完待续 统计语言模型(二)