Python unicode转义字符\u的处理
python处理字符串的时候经常用到unicode编码,特别是处理中文的时候,如下图:
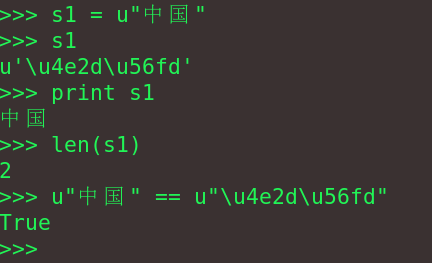
可以看出,u"中国"和u"\u4e2d\u56fd"是等价的,"中国"的unicode编码是\u4e2d\u56fd,其中\u是unicode编码的转义字符,类似\n,\r等。
在实际处理时,会碰到字符串变样了,变成了"\u4e2d\u56fd",而不是u"\u4e2d\u56fd",这种情况在从web上抓数据的时候可能会经常遇到。下图是字符串"\u4e2d\u56fd"的情况,对比上图可以看出相应的差别。
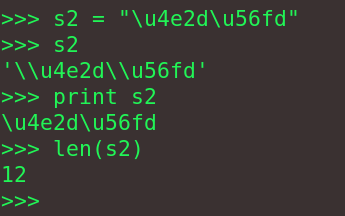
可以看出s2是一个12个ASCII字符的字符串,与我们期望的"中国"相差甚远了,该如何得到我们想要的结果呢?
方法一 利用eval函数
很容易想到将字符串转成unicode,但是ASCII转换成unicode会保持不变,这个方法不行。
比较"\u4e2d\u56fd" 和 u"\u4e2d\u56fd",前者只比后者少了u,那么"u"+"\u4e2d\u56fd",不行,变成了"u\u4e2d\u56fd"。
这时可能会想到eval函数,将字符串当作python表达式来执行,那么eval("u\"" + s2 + "\"")就变成了u"\u4e2d\u56fd",搞定。 其实"u\"" + s2 + "\"" = "u\"\u4e2d\u56fd\"",eval函数将里面的字符串当成表达式执行,那么表达式就是u"\u4e2d\u56fd"了。
方法二(推荐)
python还有更为专业的方法来解决unicode转义字符问题,那就是unicode-escape编码。
s = s2.decode("unicode-escape")
就可以了